Historically there has always been a close connection between Oracle Analytics and the database used. By pushing down to the database most of the logic it is possible to make Oracle Analytics perform better by “outsourcing” a work (data manipulation) that is best suited for a database.
Starting with Oracle Analytics Cloud (OAC) 5.7 first, and now with OAC 5.9, these ties are even stronger by exposing some of the advanced capabilities of the Oracle Database in the intuitive and simple to use interface of Data Visualization and, more precisely, into Data Sets and Data Flows.
You can find a full list of new features in Oracle Analytics Cloud 5.9 online, as well as all the previous releases new features going back to Oracle Analytics Cloud-Classic Release 17.3.3 of August 2017.
For an overview of the new features, you can read Christian Berg’s excellent blog post, which takes you through some of the main new features.
Oracle Analytics welcomes the converged database
An Oracle Database is more than “just a database” and perfectly fits into the converged database definition: a database that has native support for all modern data types and the latest development paradigms built into one product.
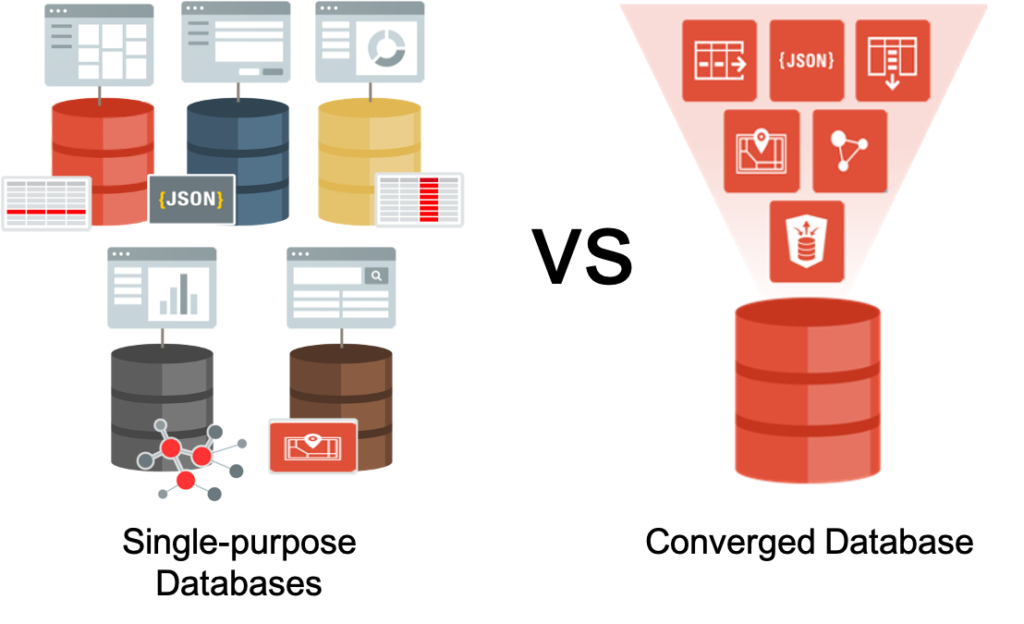
Some examples of functionalities that a converged database has are machine learning, advanced analytics functionalities, graphs, JSON, etc.
Oracle Machine Learning (OML) integration
Machine Learning (ML) isn’t new in Oracle Analytics, it has been part of the data flows for quite some time already.
What you maybe didn’t know is that it is implemented as Python code using the well known scikit-learn library. While working well and being a very capable machine learning package, because of the Python implementation, it meant that a dataset had to be extracted to the source, passed to Python to train or apply an ML model and the result sent back to Oracle Analytics for further usage (if any). It could be resource-intensive and this is probably one of the reasons for the row limits based on the Oracle Analytics Cloud instance shape you select.
To bypass some of these potential limitations, to avoid moving data around, OAC 5.7 released in July 2020 added the support for OML models already defined and trained in the database. Instead of bringing the data to ML, it was possible to bring ML to the data.
OAC 5.9 goes a step further by adding the ability to view the various supporting information existing with an OML model. All the details about the model to identify options to tune on one side, and also explainability elements on the other side. Being able to see which factors most influence the ML model, what are the key features that lead to a prediction or a class over another.
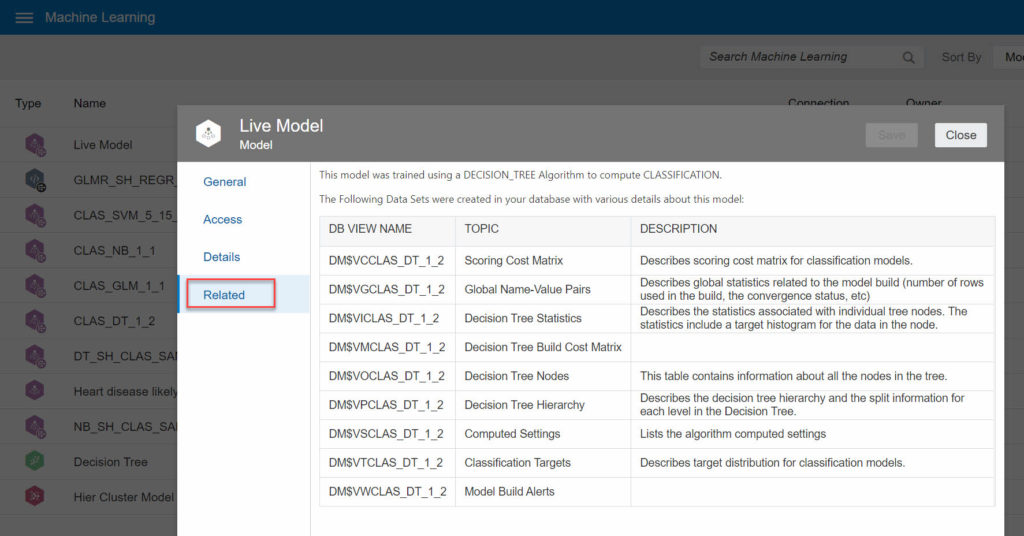
It still isn’t the end of the integration: OML models should exist and be trained in the database already, but I’m optimistic in thinking these are features coming in future releases at some point.
More advanced analytics features accessible from Data Flows
Something very similar to the OML scenario happened with some other Oracle Database advanced analytics functionalities.
OAC 5.7 came with a first “batch” of advanced database functionalities being just one click away using the Data Flows interface. It was only 4 functions: Dynamic Anomaly Detection, Dynamic Clustering, Un-pivoting Data, Sampling Data.
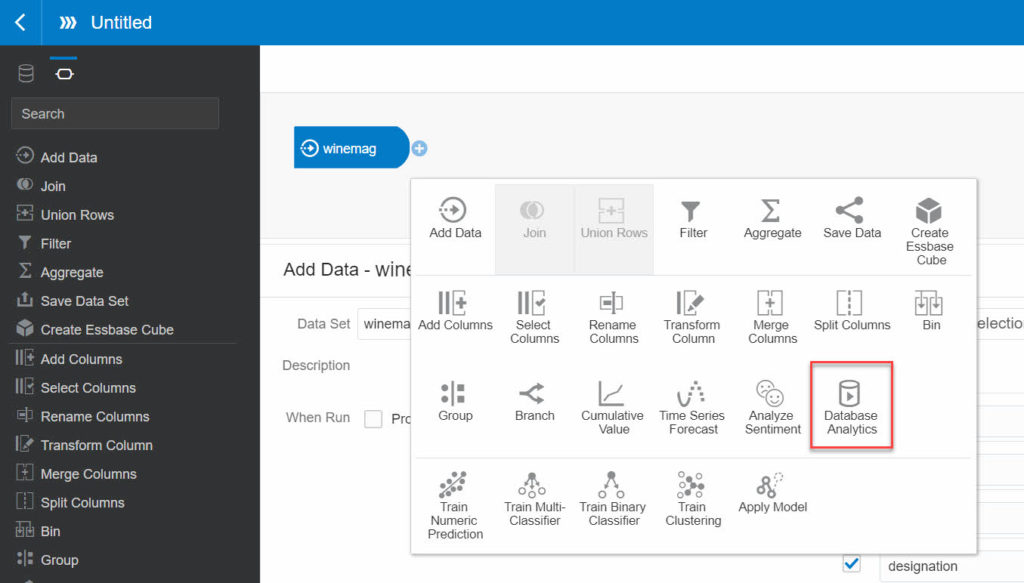
With OAC 5.9 there are 2 more functions available and one of them is extremely powerful and open new doors for the kind of analysis you will be able to do: text tokenization.
How often you have in a dataset a text field with comments or descriptions or messages and you simply ignore it because of not having the tools to perform text analysis?
But doing text tokenization you are now able in a Data Flow to extract the tokens composing a text field. By using metrics like the most frequent tokens found you can enrich your analysis with an extra dimension you were missing so far.
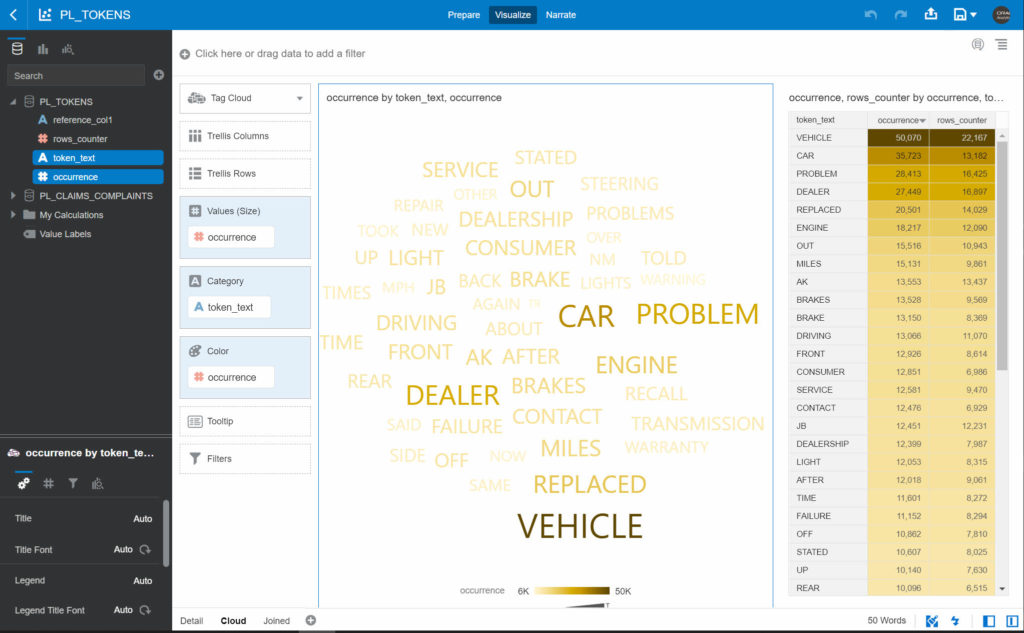
The only constraint to apply this “Database Analytics” step in your Data Flow is that the source should be in the database as well. Not a big deal, you can have a Data Flow storing your various sources data sets into the database first, and allowing you to later apply advanced analytics functions directly inside the database by adding steps to your Data Flow.
Text tokenization: a quick example
If you still aren’t convinced about the power of text tokenization, let’s have a look at a simple example. Over the past years, there is a dataset about wine that has been used and abused in all the possible ways to demonstrate ML application. The dataset has about 150’000 entries with attributes like Country, Region, Winery, Designation, Description, Variety, Points, Price.
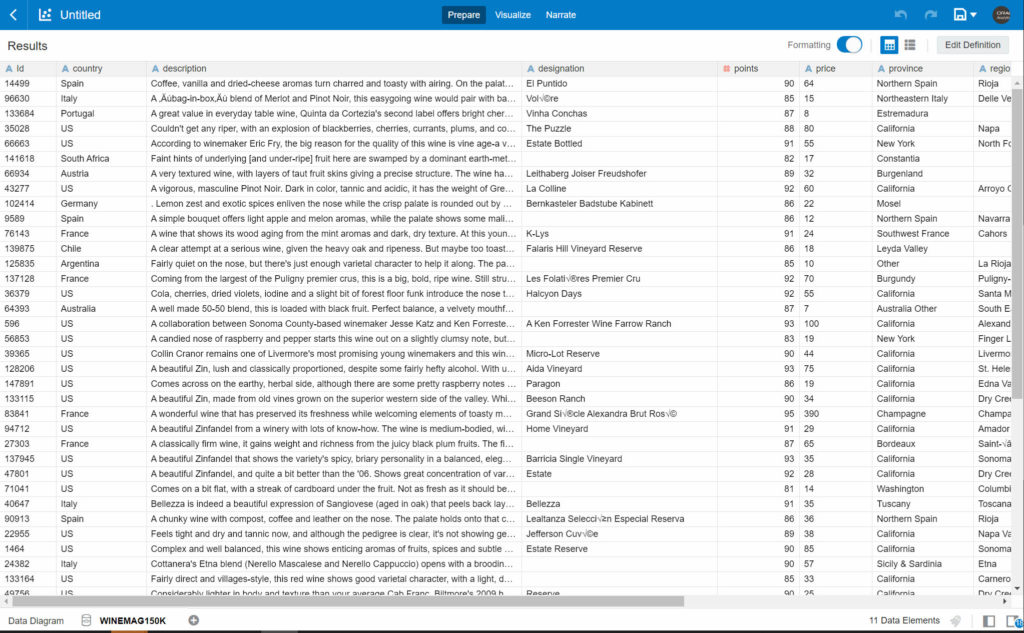
Something which is very basic, but important for most when talking about wine, is the “color”: is a wine red or white?
Often the description of wine will indicate the color by references to the tone of the colour. By applying tokenization to the description, we can extract important, single, words, and use those for analysis.
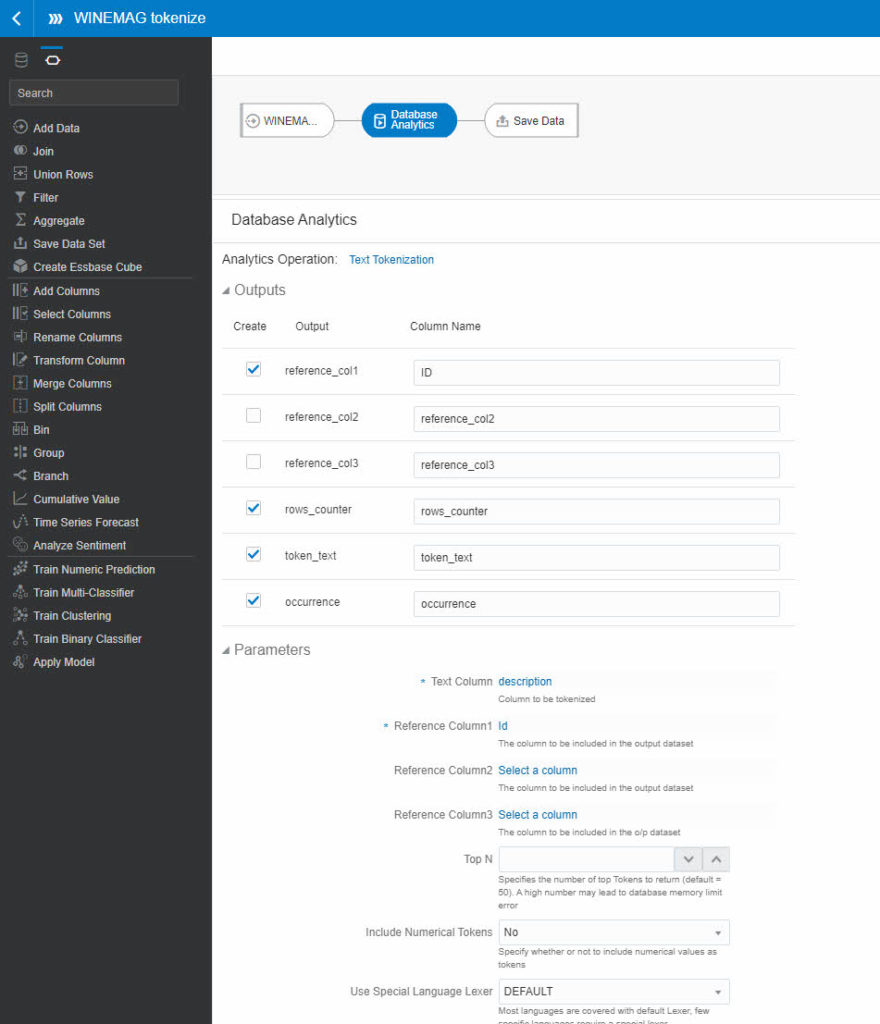
When you create a Data Flow to apply text tokenization the result is a new dataset composed of the tokens and some attributes (like the number of occurrences) and up to 3 reference columns. Because it’s a new dataset, you will use the reference columns to join back to the original dataset and be able to build projects on top of both sets: the original dataset and the one containing the tokens.
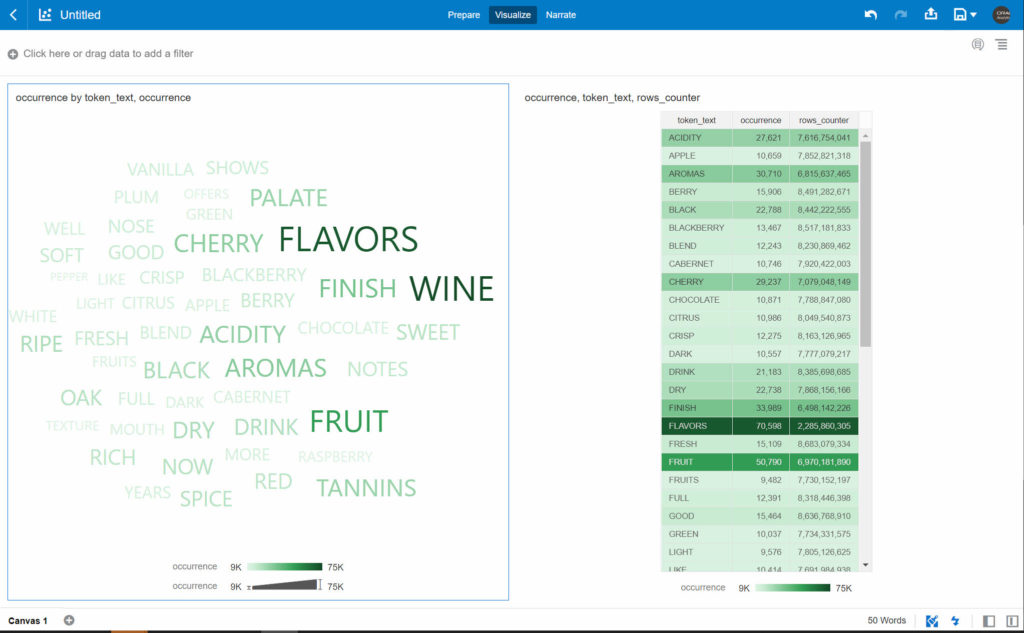
By using the result of tokenization we can also have an approximative view of the wines a country produces the most. By counting how many samples have the word “RED” or “WHITE” by country and also calculating the average points of wines with the token “RED” and “WHITE”.
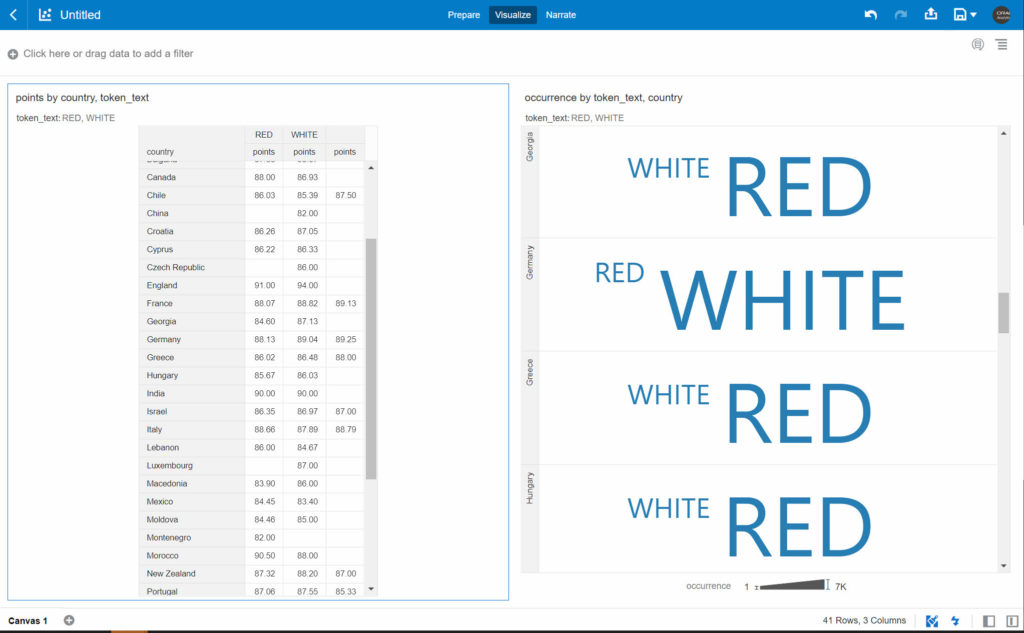
Beware, this isn’t magic and therefore the presence of the word “RED” or “WHITE” in the description doesn’t mean this is the color of the wine. Maybe the description was mentioning “red fruits” or “white chocolate” to describe the flavors of a wine.
Text tokenization makes it easier to analyze a text by counting the number of occurrences of words or the presence or absence of them but isn’t going to tell you much about the context in which the word is used: that’s a whole different process.
Step by step, more in the future?
As you can see from the above examples there are still some requirements or limitations, you can’t freely call any piece of PL/SQL you would like in your database but you are limited to what is made available to you inside the steps of a Data Flow.
It is legit to believe that future releases will keep expanding the set of advanced analytics functions made available (if there is one you desperately need, why not ask for it in the Oracle Analytics Idea Lab?). At some point, I expect to see a switch from Python-based ML to the database as well, with the ability to create an OML model from within Oracle Analytics.
And it will not stop there as other functionalities of the converged database will come (I saw it, but let’s wait for the release before to talk about those).