Earlier this week Oracle released a new cloud service: Oracle Cloud Data Science Platform. A new service making it quick and easy for data science teams to collaboratively build and deploy powerful machine learning models, leveraging assets from its acquisition of DataScience.com.
I found out about this new services reading Brendan Tierney articles:
– OCI Data Science – Initial Setup and Configuration
– OCI Data Science – Create a Project & Notebook, and Explore the Interface
After seeing the first picture and discovering that JupyterLab was part of the product, I directly connected to my cloud account and went to setup my own instance of the service to have a look and practice the AutoML capabilities included in the Oracle Accelerated Data Science SDK. This is the piece which I really wanted to test as it could change how people do Machine Learning.
Instead of having to learn tons of algorithms, python libraries and the various parameters, AutoML is going to do “everything” by itself. You load a dataset and kindly ask AutoML to “do the job”.
My first experience with AutoML: a new core dump generator
I was about to prepare a new presentation about Machine Learning and I planned to go through a lot of python to find out the best algorithms between few and find out what parameters were giving me the best accuracy possible. I planned to spend hours at this task.
AutoML was the ideal solution, all I had to do was loading the dataset and wait for Oracle Cloud Data Science Platform service to tell me the best algorithm and the ideal parameters for the best result, with a bunch of metrics to explain the choice. (You can read about this in the various blog posts online, like this one for example.)
I connected to my ADW instance, loaded the dataset from a table and started the process.
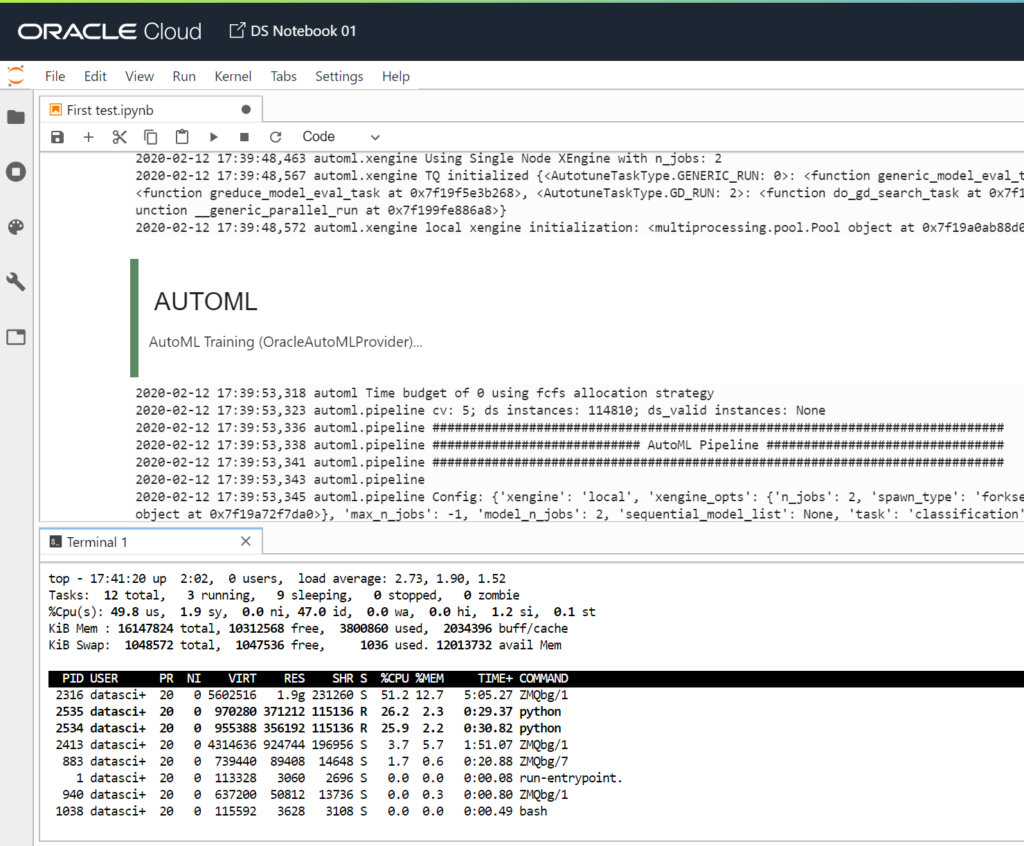
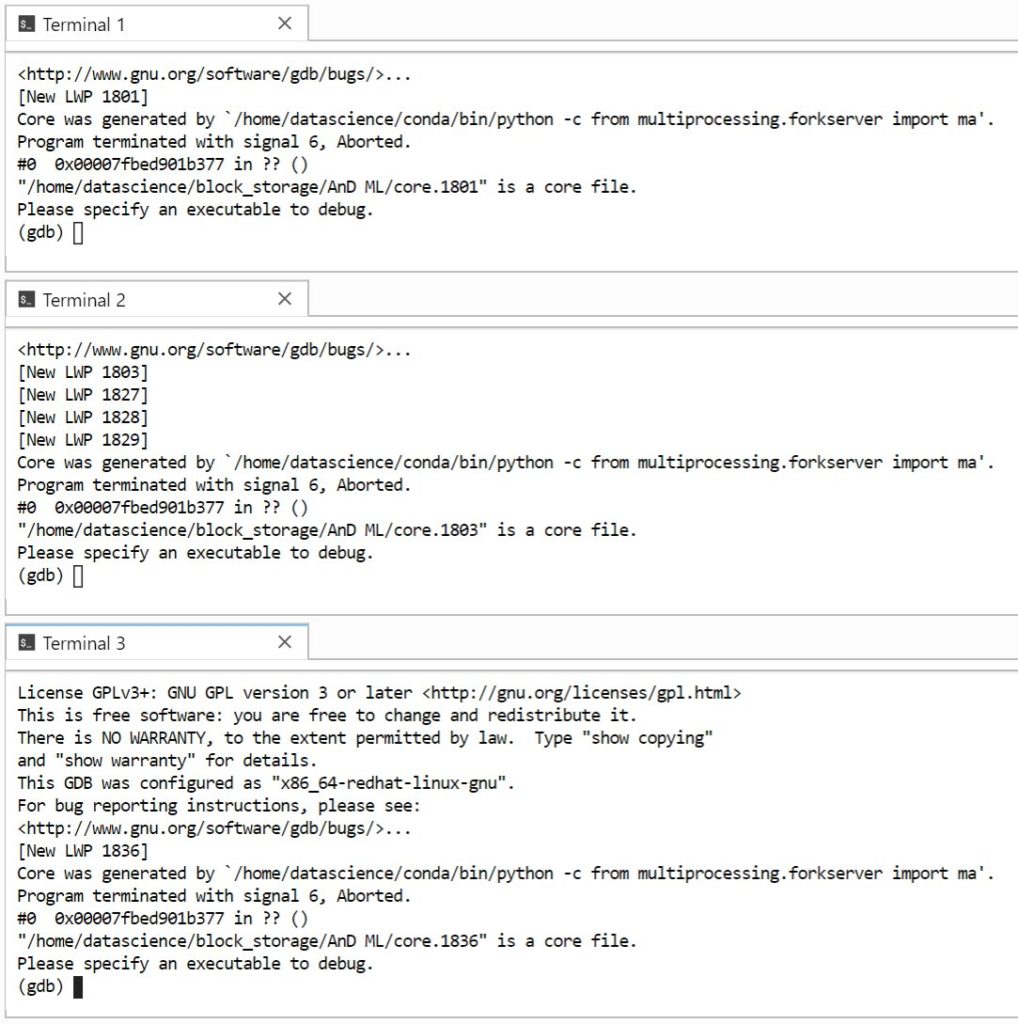
My relatively small dataset has 140k rows and 11 features. It is a simple classification problem, having to predict “true” or “false”. Whatever I do, it always finishes with a core dump if I use AutoML.
Running other python libraries like Keras, Scikit-Learn or XGboost works fine.
Using the provided examples will maybe work …
Being a new service, not having read the full documentation so far, I switched back to the provided examples to find out if I was the source of the core dumps (because using AutoML wrongly).
In every Notebook Session you have a folder named “ads-examples” which contains a bunch of notebooks and the needed data files. I picked something close to my need: “Building a Classifier using OracleAutoMLProvider”.
Didn’t look any further and executed all the cells of the notebook.
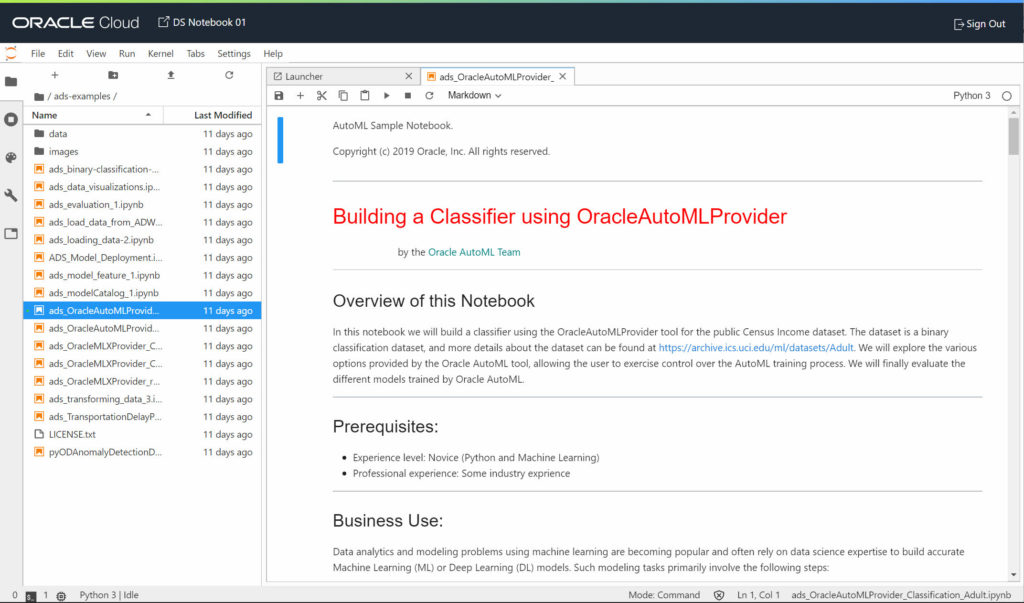
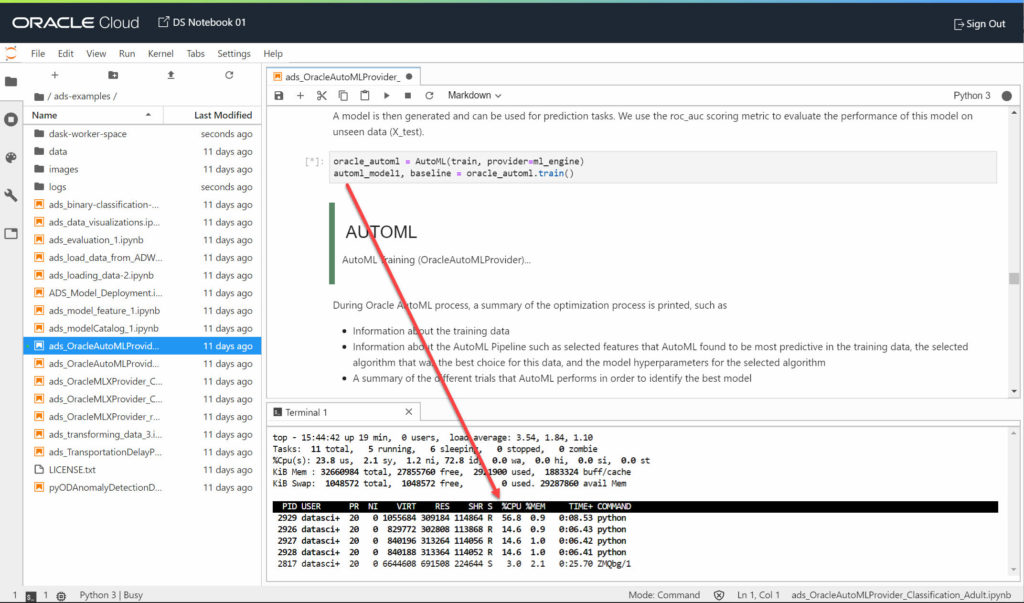
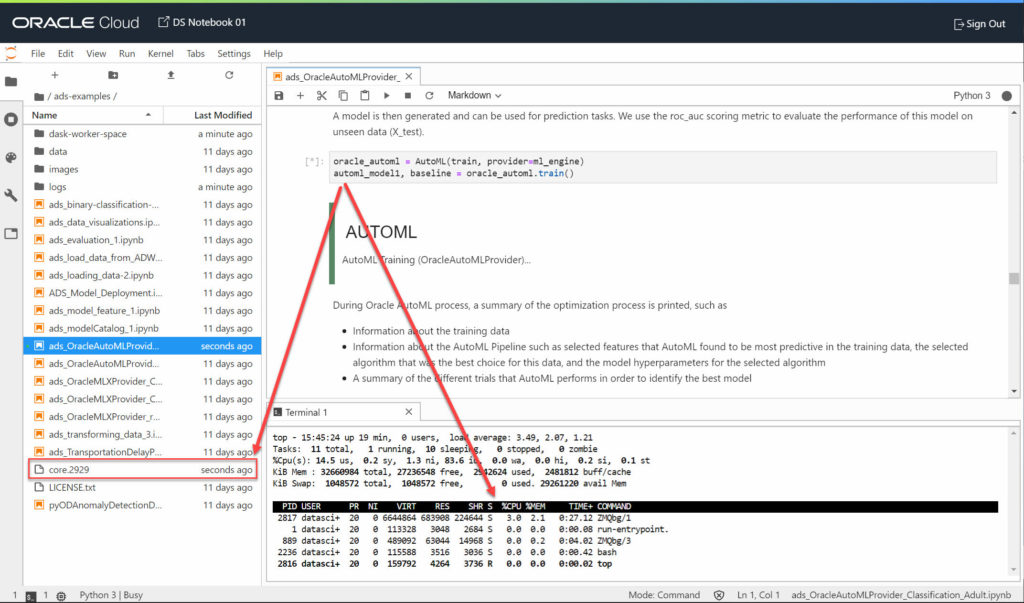
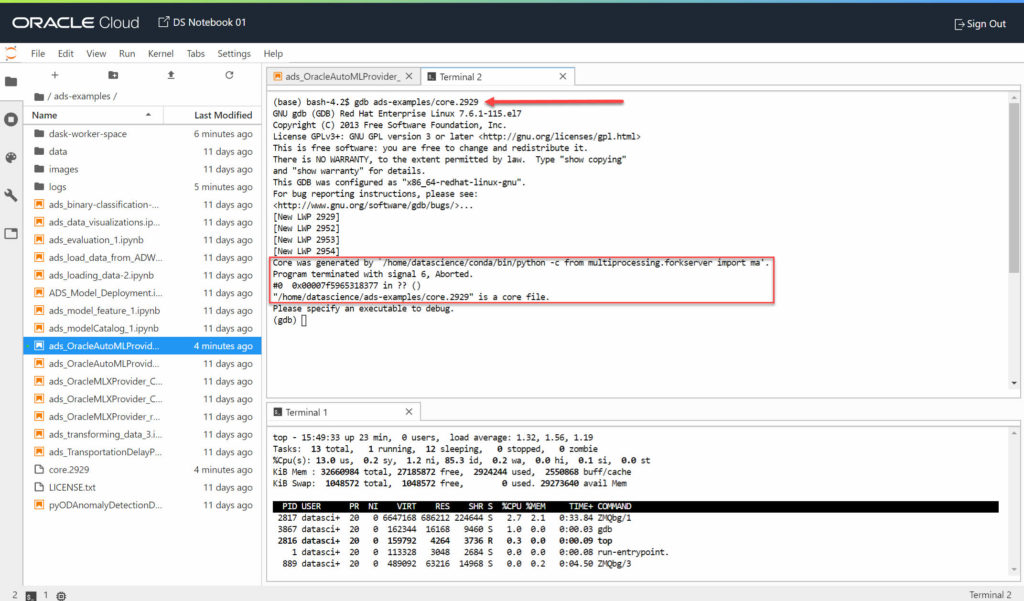
This tend to confirm I’m not the source of the core dumps: Oracle ADS is a new product and seems to be quite fragile. I’m just extremely surprised by Oracle: they provide examples which … don’t work!
It feels slow, wait … It’s a Docker container!
Because the service wasn’t really working for my ML needs, I started having a look around. Running standard python code using Keras, Scikit-Learn and XGboost felt a lot slower (5 times longer) than running in a Linux Compute Instance having the same shape of the Notebook Session.
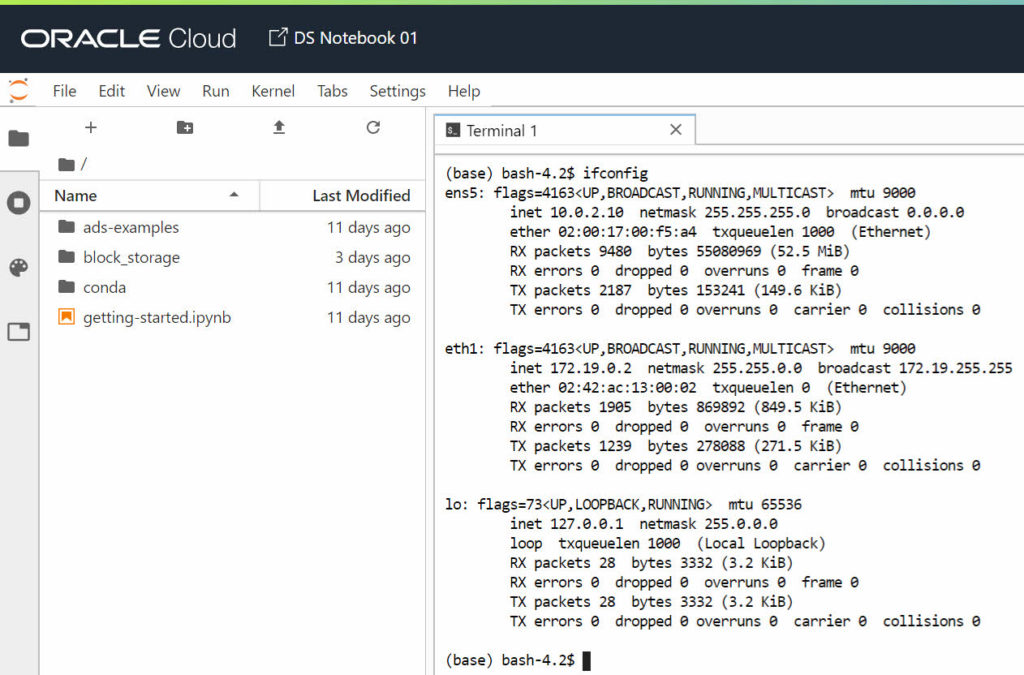
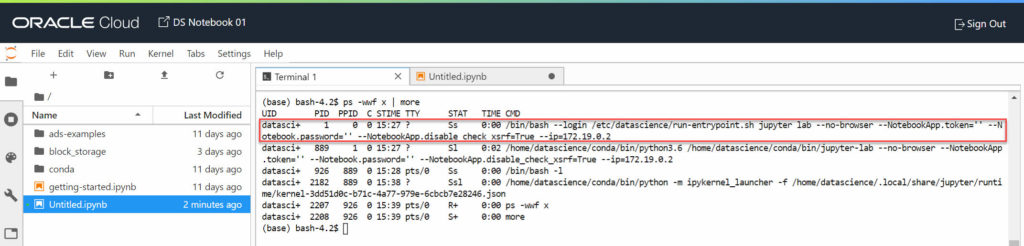
I wanted to find out if there is a full access to the Compute Instance running the service to check if something else was using “my” OCPUs power.
Surprise …
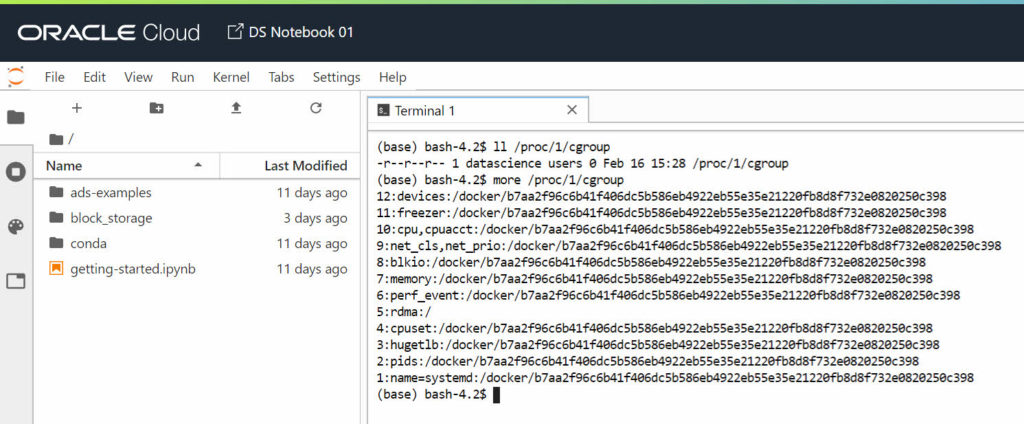
Is this JupyterHub with a Docker spawner?
The Oracle Cloud Data Science Platform gives you access to a JupyterLab notebook running inside a Docker container. My hypothesis (which I can neither confirm nor deny not having any formal architecture document of the service) is they run something like JupyterHub: the multi-user version of Jupyter notebook.
It integrates with the Oracle Cloud security using OAuth, once the user is authenticated a new Docker container is spawned by JupyterHub. Once inside the container the user has a fully isolated and independent JupyterLab environment. The only shared element with other containers (other users or when deactivating-activating the notebook) is the “block_storage” folder which is an external volume mounted inside the container.
There is no access to the compute instance
There is no way to connect to the compute instance in which the Notebook Session Docker container is running. In the same way as there doesn’t seem to be a way to use the block storage somewhere else. If you install new packages inside the Docker container, new python libraries, they are lost if the Notebook Session is deactivated and re-activated later on.
You can’t scale up or down the notebook itself while running, but you can do it by deactivating it first. Once deactivated I believe the compute instance underneath is dropped. When you activate the notebook again you are prompted to select a compute instance shape again. This allows you to add more OCPU and more RAM to your notebook. The “block_storage” folder content is preserved, because the block storage storing it is dropped only when you terminate the Notebook Session.
A good product, but more a “beta” preview than production ready
Based on my first tests and observations, this product has a good potential for users looking for Machine Learning. It promises a lot but delivers less right now.
It’s more like an early preview, a not fully stable and mature product, which allows to start experimenting a bit.
With few more iterations, and maybe reducing the number of features available, ADS could probably be a bit more stable. Right now, it really acts as a core dump generator for many things.
Even simple tasks like loading a dataset into Oracle Accelerated Data Science library from Autonomous Database isn’t fully working. If your table doesn’t have a numeric index column (I’m sorry for having an alphanumeric hash instead of numbers), Dask will fail in the loading. ADS will fall back to Pandas but … “table” is a parameter for Dask while Pandas expect a parameter named “table_name” to know which database table to load.
Give it a try, read the doc and look at the examples. Keep an eye on this service but take your time, it’s a bit too young for production usage.
Another sign the service isn’t ready…
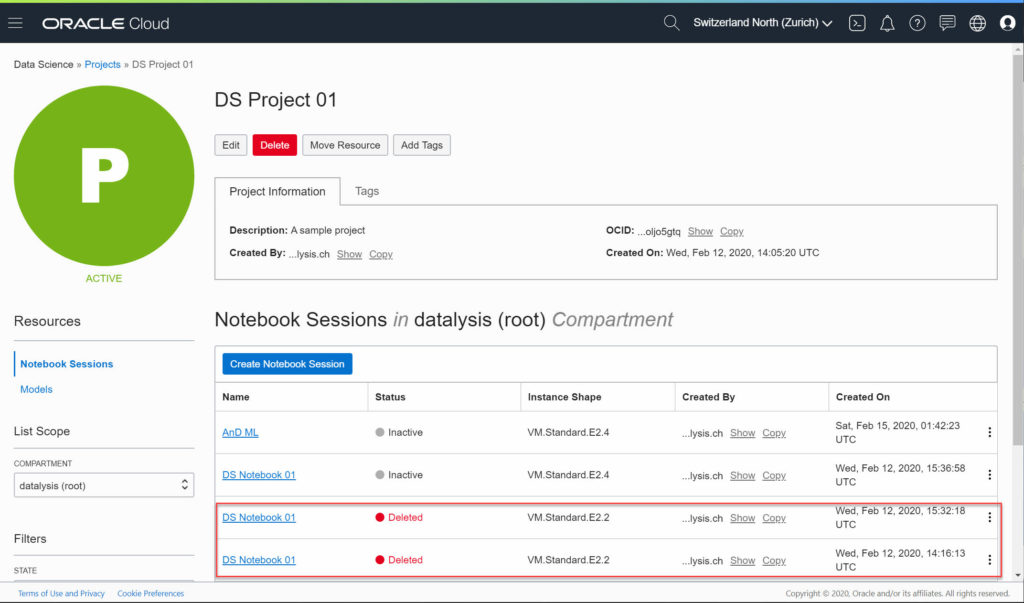
Just a list hint this service isn’t really ready for production or real usage, is also the whole behaviour when you terminate a Notebook Session. The notebooks are listed with a status of “Deleted”, the only possible action on them is to add tags (what is the point to add tags on deleted things?). Mine are there for 6 days now and still counting. What’s the point? Those notebooks actually never existed as it’s all those which failed to be created. Give me a “Delete” button to clean up or just drop them after a day they have been terminated (as they can’t be restored anyway).