Many tools and solutions support user-defined functions (UDF) to allow users to extended the functionality and functions the tool provide out-of-the-box. This feature exists for years in tools like Oracle Database or Oracle Essbase.
Oracle Parallel Graph AnalytiX (PGX) added this functionality starting with release 3.2.0 earlier this year (if I’m not wrong, this is at least the first release I saw with a configuration for it).
Why would one need user-defined functions?
Before to jump into how to configure UDFs in PGX with a full example to avoid you losing time on, sometime, vague error messages: why would you need those?
In the case of PGX the answer seems simple: the product is “young”. The query language used (PGQL) is even younger, with version 1.0 of the specifications published in November 2016.
It’s obvious they can’t implement all the native functions you can find in more mature languages like SQL or anything else who has been around for decades and used by millions of people.
UDFs can be the easier way to allow users to get the functionality the look for. Without having the developers of the tool to focus on an infinite of various requests for support of this or that thing.
Looking at one of the examples in the PGX documentation: what if you want your PGQL query to return a number in hexadecimal format?
In your Oracle Database you could use TO_CHAR(42, 'XX') and done. In PGX and PGQL there is no support for formatting values. The language for now focus on more important elements, like being able to query for that value and return it.
A quick-win for now to achieve the transformation of a number into its hexadecimal value is a UDF. In this case, the easiest way is to call a Java method of the Double class: toHexString(double d)
The full example in the documentation is available at https://docs.oracle.com/cd/E56133_01/latest/prog-guides/udfs.html .
How to write a UDF for PGX?
First choice before to start writing a UDF for PGX: what language to use?
Currently you can either use Java or JavaScript.
Java vs JavaScript
Despite having similar-sounding names, these 2 are totally different languages. JavaScript was originally named Mocha and later it became LiveScript. Finally renamed to JavaScript when Netscape and Sun (now Oracle) did a license agreement.
Java has been developed by some people at Sun (now Oracle) and, as far as I know, never changed name.
Google for many more (and correct) details and historical references
PGX is Java based, so make sense to support Java UDF. It’s a fairly popular language with a ton of existing packages and libraries allowing you to do “everything”. It must be compiled and all the referenced libraries (classes) must be available when executing it (as they aren’t embedded in the compiled code).
JavaScript is an interpreted scripting language, no compiling needed which could make it easier for simpler things. It is less structured and less strict than Java.
For the rest of this post I will focus on the Java UDFs as that’s what I had to deal with right now. Will look at JavaScript another day.
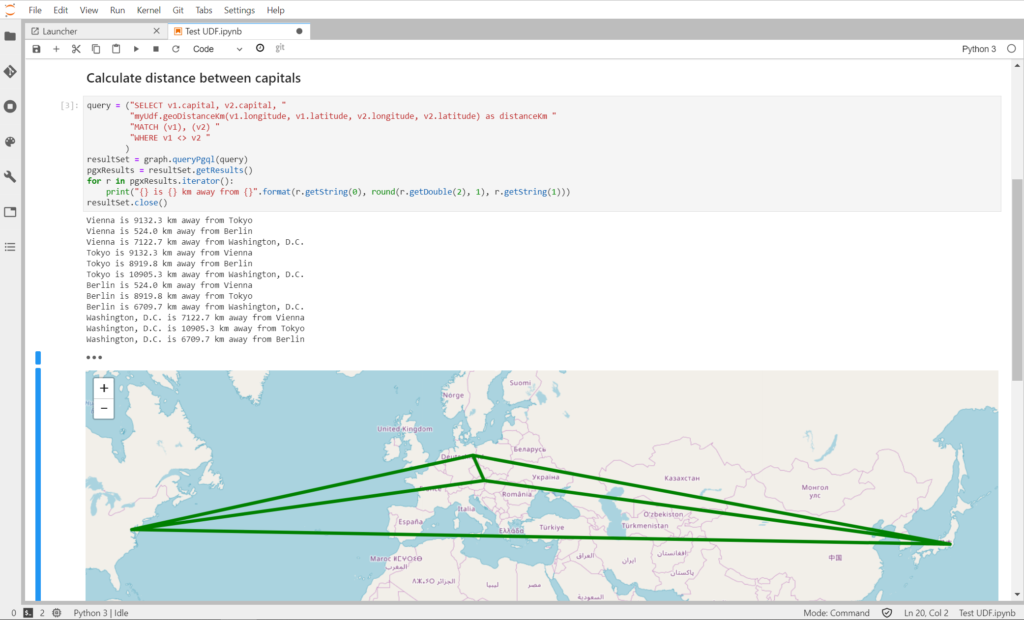
An example UDF: calculate the distance between two locations on Earth
For one my presentations I needed to be able to calculate the distance between 2 points (latitude and longitude) on Earth. Could it be 2 cities or anything else.
Disclaimer
Earth isn’t flat and neither a perfect sphere, the intent of this function is an approximate distance using a mean Earth radius, ignoring elevation above sea level, the ellipsoidal effects and everything else.
Google can cover all those details, including “flat Earth theory”
The calculation is a simple copy/paste of a function found online:
a = sin²(Δφ/2) + cos φ1 ⋅ cos φ2 ⋅ sin²(Δλ/2)
c = 2 ⋅ atan2( √a, √(1−a) )
distance = R ⋅ c
Where φ is latitude, λ is longitude, R is earth’s radius (mean radius = 6,371km).
Turning it into Java is as simple as calling the trigonometric functions on the required values after converting them into radians.
The code also provides the same function returning the distance in miles.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
package ch.datalysis.dev; public class GeoDistance { private static final double EARTH_RADIUS_KM = 6371; private static final double KM2MI = 1.609; public static double distanceKm(double lon1, double lat1, double lon2, double lat2) { return distance4params(lon1, lat1, lon2, lat2); } public static double distanceMi(double lon1, double lat1, double lon2, double lat2) { return distance4params(lon1, lat1, lon2, lat2) / KM2MI; } private static double distance4params(double lon1, double lat1, double lon2, double lat2) { double deltaLat = Math.toRadians(lat2 - lat1); double deltaLon = Math.toRadians(lon2 - lon1); double lat1Radians = Math.toRadians(lat1); double lat2Radians = Math.toRadians(lat2); double a = haversin(deltaLat) + haversin(deltaLon) * Math.cos(lat1Radians) * Math.cos(lat2Radians); double distanceInRadians = 2 * Math.asin(Math.sqrt(a)); return distanceInRadians * EARTH_RADIUS_KM; } private static double haversin(final double val) { return Math.pow(Math.sin(val / 2), 2); } } |
Java rules for UDF
A UDF must be a public static method, PGX isn’t going to instantiate an object first before to call a method on it. It must be directly accessible.
Data types are limited: boolean, integer, long, float, double, string.
Deal with it, do not expect your UDF to receive as parameter a fancy type or be able to return a custom object or anything like that. The UDF is going to be embedded into PGQL and/or Green-Marl algorithms, it must speak their language (and therefore accept and return common data types).
How to deploy a UDF practically?
Once you have your Java code compiled, and in my case Eclipse was nice enough to package it into a Jar, what do you do?
The deployment of a UDF consists of 2 main steps:
1) Make the UDF available to PGX
2) Tell PGX about its existence
A UDF Java function must be into the PGX classpath or it doesn’t exist
Despite the documentation mentioning a parameter source_location which could point to the source of the function, reality is that a Java UDF must exist in the PGX classpath to be visible and work.
If you look at the ./bin/pgx or ./bin/start-server scripts, which are used to start PGX in standalone mode or as a single instance server, you will notice a variable called CP which is used in the call to Java: java -cp $CP ...
This is the classpath PGX will be aware of, all the locations where PGX will be able to look for UDFs. You can either place your function into one of those locations or simply add a new location to that variable before it is used, pointing to a folder where you will place your functions.
In my case I added to the scripts this line: CP="$CP:/opt/pgx/udf/*" (you can use any location for those files, in my case they ended up being all into /opt/pgx/udf, which is outside of PGX itself and therefore I can share it with multiple versions of PGX).
At this point, when starting it, PGX will be aware of where to find my user-defined function if needed.
Make PGX aware a UDF exists and how it “looks like”
Having your code available is one thing, but still PGX isn’t aware of what it is and how it’s supposed to be used, what parameters it has and what it returns.
The configuration is in 2 steps: a JSON file (or many) with the details of the function(s), an entry in the PGX engine configuration file (./conf/pgx.conf) to make it aware of where to look for the UDFs JSON file(s).
In ./conf/pgx.conf the change is adding a new value to the JSON with udf_config_directory as key and the value is the location of the UDF JSON file(s) describing the functions. I tend to prefer full absolute paths here, mainly because I keep all my UDF in a common place outside of PGX.
JSON file describing the functions
Last step is the JSON file describing the UDF functions. It can be named as you prefer as long as it’s into the folder defined in the pgx.conf file (or any subfolder of that one).
The documentation has some examples but they all miss a little detail on which you can lose quite some time:
|
1 2 3 4 5 |
{ "user_defined_functions" : [ ... here you enter one or many functions ... ] } |
The file must start by defining an array with user_defined_functions as key. Without this PGX will return you error messages that it just can’t understand what that UDF is.
Once this is done everything else is like documented. You define one or many functions by adding them into user_defined_functions array. Keep in mind that for a Java UDF the source_location value has no effect as the Java code must be in PGX classpath already.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
{ "user_defined_functions" : [ { "namespace" : "myUdf", "function_name" : "geoDistanceKm", "language" : "java", "implementation_reference" : "ch.datalysis.dev.GeoDistance", "source_function_name" : "distanceKm", "return_type" : "double", "arguments" : [ { "name" : "lon1", "type" : "double" }, { "name" : "lat1", "type" : "double" }, { "name" : "lon2", "type" : "double" }, { "name" : "lat2", "type" : "double" } ] }, { "namespace" : "myUdf", "function_name" : "geoDistanceMi", "language" : "java", "implementation_reference" : "ch.datalysis.dev.GeoDistance", "source_function_name" : "distanceMi", "return_type" : "double", "arguments" : [ { "name" : "lon1", "type" : "double" }, { "name" : "lat1", "type" : "double" }, { "name" : "lon2", "type" : "double" }, { "name" : "lat2", "type" : "double" } ] } ] } |
The obvious parts are the description of the expected parameters (with name and type, so that error messages returned by PGX can be explicit) and the return type of the UDF as well.
Your UDF can have in PGX a completely different and independent name than what it has in real: inplementation_reference and source_function_name point to the Java side of things with package and Java function name, while namespace and function_name sets how this UDF is made available in PGX.
Does it work? Yes!
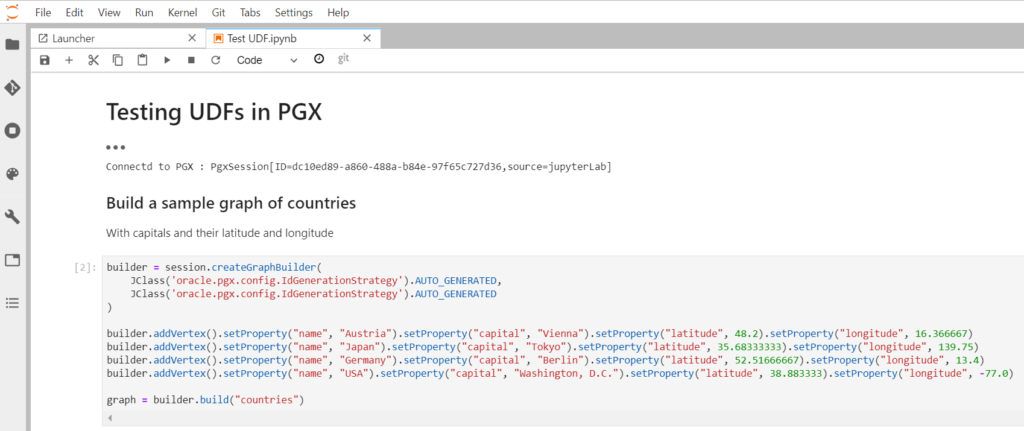
By creating a sample graph representing some countries with their capitals and latitude and longitude locations, it will be possible to test the UDF function which calculate the distance between 2 locations in a PGQL query.