Graph databases: who hasn’t heard, so far, these words?
The newest pretty shiny tool for data scientist, the latest addition to the analytical toolbox after big data solutions few years ago.
So far it seems to still be a niche solution, too new to be widely adopted. Which also means it’s the perfect timing to take this train and not miss it.
I jumped on that train “seriously” in the last weeks and here, and in some future posts, you will find my findings. This is just a quick intro on what will make my work with graphs possible, the graph “brain”.
Why graph databases?
You can for sure do the same kind of analysis a graph database allows you to perform on your relational database. But you will have to write tons of code and it will, probably, perform quite badly.
Relational databases are excellent for their job, and nobody is saying relational is dead. But you can’t expect they keep being excellent for analysis or activities where other technologies / models would fit better. Same story with cubes: sure, you can store in your database data and perform analysis on it, but for some activities you will never outperform or even get close to a good Essbase cube.
Same for graph databases engines: they are optimized for performing analysis on graphs and managing data based on graphs composed by nodes (aka vertex) and edges each one having properties and labels.
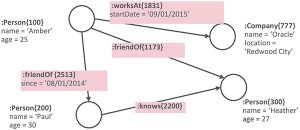
A sample property graph
There are multiple engines available on the market to store and manipulate graphs. I admit I just knew Neo4j and I didn’t search longer as Neo4j can easily be used to get started with a graph and get your hands dirty playing with graphs.
docker run -d -p 7474:7474 -p 7687:7687 -P --name neo4j neo4j:latest
Open a browser and connect to http://<docker host>:7474 and there you are!
Follow instructions on screen and enjoy graphs. Guided tutorials and a web visualization of your graph make it easy to get started with.
Oracle graph solutions
Oracle joined the party with their property graph solution: PGX, the acronym of Parallel Graph AnalytiX.
Actually, PGX can be a standalone graph tool, but in the current situation it is more the brain of the graph implementations Oracle used in various tools. It’s the “tool” performing operations on graphs in-memory, but doesn’t provide storage directly. Storage (read and write) is provided by external solutions.
The description of what it does sound great, the documentation is nicely written with lot of examples.
What is PGX?
PGX is a toolkit for graph analysis – both running algorithms such as PageRank against graphs, and performing SQL-like pattern-matching against graphs, using the results of algorithmic analysis. Algorithms are parallelized for extreme performance. The PGX toolkit includes both a single-node in-memory engine, and a distributed engine for extremely large graphs. Graphs can be loaded from a variety of sources including flat files, SQL and NoSQL databases and Apache Spark and Hadoop; incremental updates are supported.
(http://www.oracle.com/technetwork/oracle-labs/parallel-graph-analytix/overview/index.html)
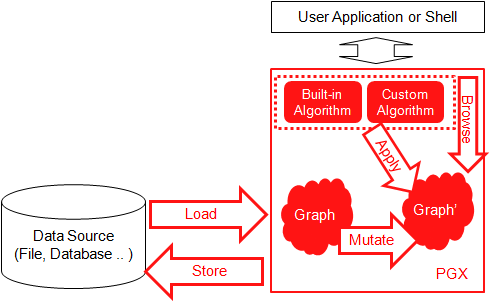
PGX overview
As you can see from the generic structure of PGX, it’s a client-server “kind of” solution where the client will interact with the PGX engine (the server) and this one will then, if required, interact with different kind of storage to load or store graphs.
You can also build an ephemeral graph, on the fly, from the client and use it for the required analysis in memory and never store it anywhere.
PGX clients
Multiple clients already exist: PGX shell, java, javascript, python, Zeppelin notebook.
This list will grow in the future as the exposed API and REST interface can easily be used by other languages or tools.
PGX shell is probably the most complete and native one followed by the Java API. The python module (still didn’t find a link to download and install it directly, but you can find it in PGX embedded in Database 12cR2) seems to be using the Java API, so all the same functionalities can be exposed, even if the current status is maybe more limited.
The PGX Zeppelin interpreter is still kind of work in progress: if PGX isn’t local but connecting to a remote instance some functions do not work anymore (there isn’t a full support of the shell functions when connected remotely via Zeppelin).
PGX data sources
The list of supported sources so far seems to be: flat files (filesystem), SQL (database), NoSQL, Spark and HDFS.
Here the issues starts as apparently not all the sources are available in all the PGX distributions.
So far, I used the flat files and SQL loading from the database: globally worked fine. I’m probably not going to look into NoSQL, Spark and HDFS support as I don’t have these tools on my Docker images.
Multiple version and distributions
If in theory and on paper PGX is all nice and cool, there are some issues ….
So far there seems to be multiple different versions both in terms of version number and functionalities.
In Oracle Database 12c Release 2 (12.2.0.1.0) you have PGX version 2.1.0 with support to source (load) graphs from the database or filesystem (based on the list of JAR files I saw).
In Oracle Big Data Lite Virtual Machine 4.8 you will find PGX version 2.4.0 with support to source graphs from the filesystem, NoSQL and HDFS.
If you download PGX from the OTN website you get version 2.4.1 with support to source graphs from filesystem apparently only.
If you apply “Patch 25640325: MISSING PGQL FUNCTION IN ORACLE DATABASE RELEASE 12.2.0.1” to your 12c Release 2 database you will end up with PGX 2.4.0 and same sources for graphs: database and filesystem. The patch in addition to a newer version bring support for PGQL.
To make it short: 3 versions, 3 different data sources = not easy to really test all the feature of PGX easily. Double check the documentation for notes on top of pages with limitations of which release support the functionality (mainly when related to graph loading).
The version provided with Big Data Lite virtual machine must be the one named “Oracle Big Data Spatial and Graph” package, while the one delivered with database 12cR2 must be the one named “Oracle Spatial and Graph” package.
Apparently, reading posts on OTN forum, I’m not the only one dreaming for PGX 2.5.0 merging the current versions and providing support for all the sources making it easier to test and compare options.
I can understand and agree that licensing will be different and can justify support for different or limited sources, but the software must be developed as a single solution to guarantee compatibility and flexibility.
How to use it?
PGX can be used in multiple ways as you can see from the following picture I took from the doc.
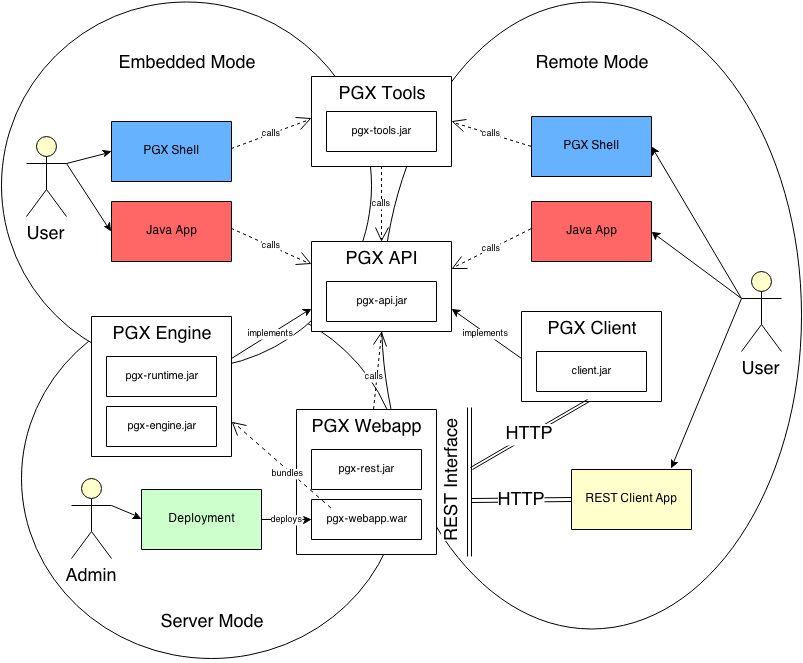
Usage of PGX
The simplest and quickest way is to use the PGX shell you get with PGX (./bin/pgx). If you take the OTN version all it takes is to unzip the file, meet the requirements (in the end JAVA mainly) and you are ready to start with the shell.
How to exit the PGX shell?
It took me some time to find how to exit the PGX shell, all the classical “exit”, “quit”, “stop”, “please let me out” didn’t work …
Finally found that System.exit(0) works fine for that.
In my case I decided to use Apache Zeppelin as there is a PGX interpreter provided by Oracle, and Zeppelin also support Python (by using the pyopg module), SQL (by using a JDBC interpreter) and few other things. This make Zeppelin a good way to document and test commands, because you can have a nice documentation using markdown and next to it code you execute on the fly.
An extra argument justifying the usage or Zeppelin is the Oracle Lab Data Studio application which will come at some point in the coming months (like always with Oracle: not guaranteed) and which will support to import Zeppelin notebook. So, nothing will be lost …
Must be noted that, out of the box, there is no visualization plugin available in Zeppelin so far. Oracle Lab Data Studio will provide that out of the box.
You can of course get something similar by using Jupyter, another notebook application (python will work fine but didn’t look at porting the PGX interpreter from Zeppelin to Jupyter for now).
So far, I have a setup with Zeppelin, Oracle Database 12cR2 and a PGX server running in three Docker containers and communicating together. It’s the closest to what a standard “enterprise” setup would look like I got.
I’m still finalizing the setup and will write about it in a future post, maybe after the OTN PGX release will also support sourcing from the database. The Docker images will also be provided as they are extensions of existing images but pre-configured to work together (SSL certificates etc.).
Where to start? Documentation?
The documentation is really nicely done. Multiple tutorials making it simple to follow. Some examples and use cases. All the details about the API and how things work.
It’s definitely the best place to get started with PGX: https://docs.oracle.com/cd/E56133_01/latest/index.html
Stay tuned for more content about PGX and properties graphs in general, I’m going to work on this topic for quite some time…