Connection pools, these little basic, but mandatory, things we all have in our RPD. For normal usage we generally do not really pay attention to it: enter a host, username and password and done, you are connected to the database and move forward to other tasks.
But … there are still misunderstandings on how they work or how to use them.
Multiple connection pools in the same database but OBIEE always use the first one: why?
Lately saw few times people misunderstanding their role, the relationship between the database object and the contained connection pools and ending up with error because queries were executed against the wrong connection.
For a given database object in the physical layer OBIEE will always use the first connection pool (in order top-down) with a read privilege for the authenticated user when retrieving data for an analysis, prompt etc.
That’s how it works!
You can have multiple connection pools inside the same database object and they can use different database users with different access and you can import metadata from each one and model everything like that. But OBIEE will just ignore all that and use the first one.
The Admin tool will not warn you about it, in the same way it isn’t going to warn you if you don’t have a connection pool for a database.
As you can make physical joins between tables of different databases in the physical layer, if you need to source tables from 2 or more different schemas (so using different login/password for the database) you must create different database objects in the physical layer.
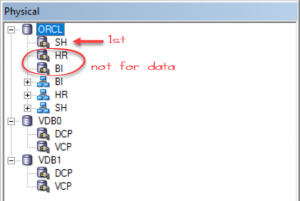
Only the 1st one will be used to retrieve data for analysis.
Multiple connection pools mainly for variables init blocks
The general practice is to create multiple connection pools for the same database object to split “data” and “variables” pipes. The first one being used to retrieve data while the second (or all the others) are used by init blocks to initialize variables.
As variables are often initialized at the login it would be a problem if your query is stopped in queue waiting the connection pool to be available because someone is running huge queries.
So, to avoid delays on login. using an independent connection pool which is only used by init blocks is a good practice. Variables queries are generally fairly small and quick and return little data, so there are less chances (as long as the database works fine) to end up in queue waiting for “availability” of the pipe connecting to the database.
This good practice is “enforced” by the Admin tool as by default the option “Allow first Connection Pool for Init Blocks” isn’t checked, meaning that you will not be allowed to select the first connection pool when defining variable init blocks. As it just take a right click > duplicate to have a second connection pool, it’s easy to follow this good practice.
tl;dr
- A database object in the physical layer has at least a connection pool but can also have more than one.
- For a given database object in the physical layer all the analysis will use the same connection pool (direct database request obviously works in a different way).
- The used connection pool (for analysis and prompts) is the first one with a “read” privilege for the user wanting to use it (based on the order in the RPD from the top to the bottom).
- A good practice is to use a separate connection pool for variables initialization blocks.
- Instead of joining tables of different database objects because of 2 credentials on the same database, consider to grant select access to a single user to all the objects on the database side. This will allow OBIEE to push down the query fully on the database side instead of having to perform joins of datasets at the BI Server level (being slower).
Hi Gianni,
Does it help to have a separate connection pool for the same set of physical tables? To be specific, we have both analysis reports and mobile app reports hitting the same subject area and hence, via the same connection pool fetching data from physical tables. For faster performance in mobile app, would it help if we create and new subject area fetching data from db via new connection pool?
I read in a forum, it might not and that in such a scenario number of connections should be increased. Please advise.
Hi,
As you can’t define a connection pool based on the subject area, duplicating the subject area isn’t going to help you. If the account connecting to the DB is the same one for both your analysis and mobile app then speak to your DBA to find how much you can increase number of concurrent connection for the same single connection pool without affecting the DB. I would also not be so sure about any performance improvement: you will have improvements only if your queries are now queuing and waiting to go through the connection till the DB, and you can monitor that in OBIEE to find out if it’s the case.
Could you please explain how the direct database request works in a multiple connection pools for a data source as I am getting an ambiguous error in the direct database request report for one connection pool even with different connection pool names.The variable connection pool is working fine.Thanks
A DDR doesn’t care much if you have multiple connection pools as it request a full name of a given connection pool. So if you have 1 or many, the name you enter anyway always reference a single one.