While I was cropping a screenshot for the previous post about Time Series functions in OBIEE I discovered something new in OBIEE 12c I completely missed till now.

Sequence Numbers tab on Time Dimension logical level: a OBIEE 12c U.R.O. (unidentified RPD object)
In every logical level of a time dimension hierarchy (except for the grand total level) there is an extra tab named “Sequence Numbers”.
Sequence Numbers for Time Dimension’s logical levels
What is this tab and what kind of values does it contain and allow us to change/set ?
Time to look in the documentation….
Adding absolute or relative sequence numbers to time dimensions optimizes time series functions and in some cases improves query time.
By default Oracle BI Server uses a complex RANK Physical SQL expression to generate sequence numbers for time dimensions. Adding an absolute or relative sequence number to the time dimension’s logical level provides direct column references in the Time dimension table that contain the precomputed results of the rank expressions. This mapping, while optional, generates a simpler query that is easier for Oracle BI Server to execute against the data source.
(source: Fusion Middleware Metadata Repository Builder’s Guide for OBIEE 12.2.1.2.0)
The doc is quite explicit, going back to the previous post on Time Series functions we saw OBIEE generate multiple queries, the first one uses the chronological key to sort rows and assign a unique number to each one by using a ranking function. So, what these sequence numbers do is replace that step, avoiding to generate a query calling a ranking function.
Let’s see all this more in detail, starting from the beginning…
By default nothing is set and it’s optional
By default it’s empty
When first checking the tab it’s empty but we can see 2 different options:
- Absolute : allow to set a logical column, only numeric columns are valid options in the drop-down list
- Relative : allow to set for a parent logical level (1st column) a numeric column (2nd column), this column is a numeric sequence relative to the parent logical level selected
First thing to note: the “Relative” part is available only when configuring a logical level having parents’ levels other than the grand total.
Practical example
Let’s see a practical example to make it more clear and also highlight the difference between absolute and relative.

This is the example time hierarchy I’m using: Year – Quarter – Month – Day
And now let’s look directly at how I configured all the sequence numbers (I defined all of them).

All the possible sequence numbers at all levels are set.
“Year” being the first level after the “grand total” it only accepts an absolute sequence, it makes sense as at this level relative and absolute sequence would be strictly identical.
Going down to “Quarter” it’s possible to set an absolute one providing a unique value for any given quarter and one relative. This one is relative to the only available parent level “Year” and so it represents a number being unique for each quarter only for a given year: it’s a number between 1 and 4 for example.
The “Month” level accepts, as any level, an absolute one and this time 2 relative sequences: one relative to the “Quarter” level, the direct parent, and one relative to the “Year” level which is an ancestor of “Month” (grandfather talking by “family-relationship”).
Last but not least, the detail level is “Day”, here an absolute one is possible and 3 relative sequences for “Year”, “Quarter” and “Month”.
What’s different from a value point of view between absolute and relative sequences?
Absolute sequences
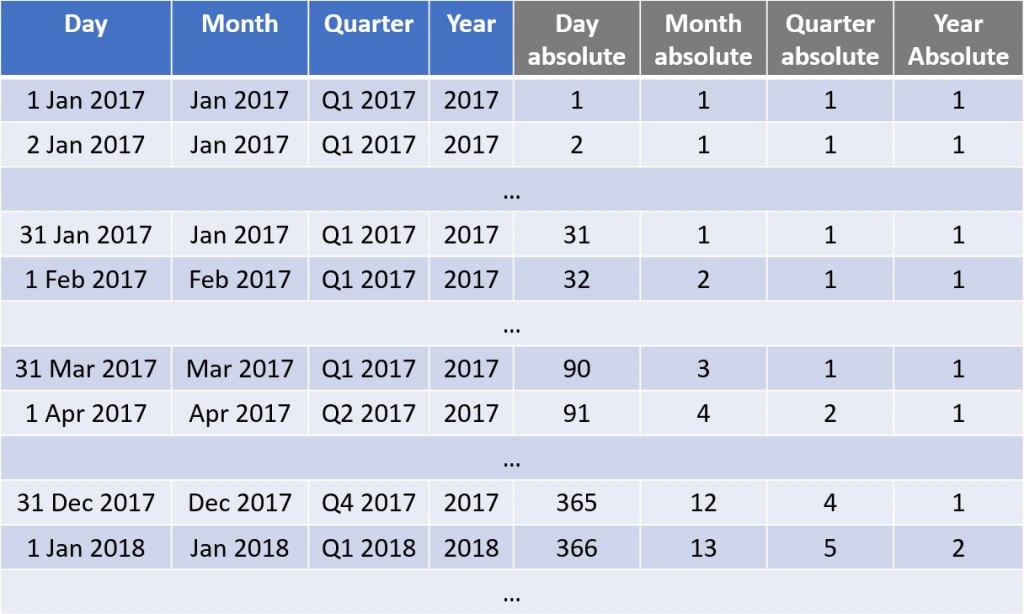
An example of absolute sequences values.
The key element is uniqueness of a value globally in the whole dimension. To keep it simple I started my sequences with 1 all the time (used DENSE_RANK to generate them in the database), but for example for years using the year number (4 digits !!) is also a way to get a valid absolute key.
Also, do not forget that these sequences must not have gaps! If for any reason your model never has the month of December because you are on holidays (I double it, just an example), you can’t skip a number for the not existing month: values must be contiguous. That’s because Time Series functions are done by mathematical addition or subtraction on this number to move backward or forward in time, so OBIEE must not end up on a missing sequence value.
Relative sequences
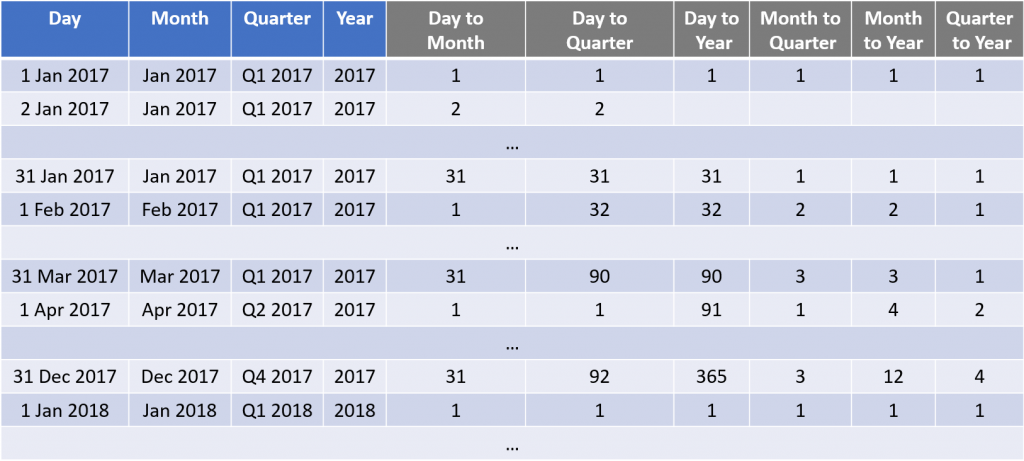
Example of relative sequences.
As you can see there are more possible relative sequences than the number of absolute ones: the number of all the possible relative sequences is (N * (N+1)) / 2, where N is the total number of logical levels of the time hierarchy minus 2 (including grand total). In my case I have 5 levels (grand, year, quarter, month, day) in the hierarchy, so N = 5-2 = 3, and (3 * (3+1)) / 2 = 6 is the number of my relative sequences.
The same rule of contiguity of numbers as the absolute sequences applies here as well: no gaps allowed in sequences!
The main difference is that the sequence restart from the beginning every time the value of the level it is related to change. So, the sequence of “Day” relative to “Month” goes from 1 to 31 (or 30 or 28/29) depending on the month. The sequence of “Month” relative to “Year” goes from 1 to 12. And so on …
It is important to always restart the sequence from the same number as OBIEE can use these relative sequences to make sure it is matching the right row when doing calculations at a different level, for example to make sure it’s matching January (of 2017) when doing a “year ago” on January 2018.
Physical query: how is it impacted?
As the documentation “sell” us that sequences can “optimizes time series functions and in some cases improves query time” I’m really curious to see the real impact on the physical query OBIEE generates: how is it difference and “optimized” / “faster” ?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
WITH SAWITH0 AS (select T1485.SEQ_MONTH_ABS as c1, T1485.ID_DATE as c2, T1485.MONTH as c3, T1485.ID_MONTH as c4 from SEQNUM_DIM_CALENDAR T1485), SAWITH1 AS (select D1.c1 + 1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4 from SAWITH0 D1), SAWITH2 AS (select distinct T1485.SEQ_MONTH_ABS as c1, T1485.ID_MONTH as c2, T1485.MONTH as c3 from SEQNUM_DIM_CALENDAR T1485), SAWITH3 AS (select sum(T1504.SAMPLE_MEASURE) as c1, D3.c3 as c2, D3.c2 as c3 from SEQNUM_FACT_SAMPLE T1504, SAWITH1 D4, SAWITH2 D3 where ( T1504.ID_DATE = D4.c2 and D3.c1 = D4.c1 ) group by D3.c2, D3.c3, D4.c3), SAWITH4 AS (select sum(T1504.SAMPLE_MEASURE) as c1, T1485.MONTH as c2, T1485.ID_MONTH as c3 from SEQNUM_DIM_CALENDAR T1485, SEQNUM_FACT_SAMPLE T1504 where ( T1485.ID_DATE = T1504.ID_DATE ) group by T1485.ID_MONTH, T1485.MONTH), SAWITH5 AS (select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5 from (select 0 as c1, coalesce( D1.c2, D2.c2) as c2, coalesce( D1.c3, D2.c3) as c3, D2.c1 as c4, D1.c1 as c5, ROW_NUMBER() OVER (PARTITION BY coalesce( D1.c2, D2.c2), coalesce( D1.c3, D2.c3) ORDER BY coalesce( D1.c2, D2.c2) ASC, coalesce( D1.c3, D2.c3) ASC) as c6 from SAWITH3 D1 full outer join SAWITH4 D2 On D1.c2 = D2.c2 and D1.c3 = D2.c3 ) D1 where ( D1.c6 = 1 ) ) select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5 from ( select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5 from SAWITH5 D1 order by c3 ) D1 where rownum <= 65001 |
Well … not really a surprise but there aren’t big changes: the DENSE_RANK are gone and the sequences columns are used instead (compare with this). Nothing else really, all the WITH blocks are still there, just retrieving a column instead of calling the ranking function. So the potential of optimization and performance improvements is limited.
Which sequence is used based on the Time Series function?
I didn’t test 1024+ cases to define a model but just looking at few queries and adding some logic the global rule of thumb I saw is the following:
- TO DATE : uses the relative sequence for the level asked in the TODATE
- PERIOD ROLLING : absolute sequence at the “rolling” level, in this way can go through years for example when doing 12 months rolling calculations as the sequence doesn’t care about end/beginning of years
- AGO : absolute at the defined level and relative for underneath levels to make sure to match the same point in time in the past
Performance optimization: for real?
Do not expect this new feature to make miracles! If you have slow analysis with Time Series functions and you set these sequences I suspect they will still be slow because the problem is somewhere else.
Time dimension is generally small (time isn’t relative to your business), a month has a given number of days, a year a given number of month and so on. Time dimension granularity is up to the day (the time component I would personally store it somewhere else instead of including every single second of every day of every year in a time dimension).
So, even if you have have 10 years of data, you end up with ~3650 values. Any database can easily run a ranking on such a small set of data (mainly if you make sure to properly design your table having proper chronological keys). Therefor the performance impact is really relative and limited, Time Series functions being “slow” is mainly time spent doing the aggregations or applying business logic on facts than ranking functions.
If you are a follower of the Robin Moffatt’s school for performance in OBIEE, details here or here, you will be able to clearly analyse and quantify the impact of these sequences numbers on your analysis.
If you were hoping for an impact like the miracle switch “please_go_super_fast = 42;” in the nqsconfig.ini file of OBIEE , better to continue to hope, doesn’t cost anything … (we all agree such setting doesn’t exist, right?)
But don’t get me wrong: it will not make it any worse, I can hardly imagine worst performance using sequence numbers compared to ranking functions called live on the chronological keys.
Is it worth to create these columns and set them in the RPD?
My opinion? Yes! Doesn’t cost a lot.
The time dimension is a quite static and small, so adding more columns, even if it can easily be lot of columns (I only have Year-Quarter-Month-Day and I have 10 extra columns in the dimension for sequences), is cheap and a one-shot activity. It’s simple columns, numbers, generated by ranking functions without requiring extra business logic (nothing you don’t already have in case you manage multiple alternate calendars like a fiscal one etc.).
The cost and time effort to create these columns in the database and populate them is so little that it’s worth to do it also because it will prevent strange Time Series functions behaviours because of a wrong or missing chronological key. When designing the time dimension you have less chances to select the wrong sequence than the wrong chronological key.
You can also decide to only create few of them if you want, they are all optional and nothing mandatory, but I still believe it’s better to be consistent and if you start, make it everywhere. In this way you can expect a more consistent behaviour on the OBIEE side with similar queries being generated (will make your life easier when trying to debug things).
Very interesting, thanks for informing about this feature. Speaking of “hidden” features, do you know anything about the Data driven fragment selection in 12c? I have tried to find out but no one seem to know…
https://community.oracle.com/thread/3997082
Hi Gustaf,
I heard few things about it but still didn’t play with it directly myself. Will have a look and if I find out enough things post about it.
PS: if it’s your post on OTN, how does it end up in that “OBIEE12c” group instead of the official OBIEE forum? Not many people on that group …
I tried the same way, but the query still used the old way even I set up the sequence number on each level. Is there any setting needed in OBIEE, so it will choose sequence number instead of the old way?
OBIEE keep the control on which query it will generate. There isn’t anything else I had to set to make it use the sequence numbers once setup. So you maybe have something in your analysis which tell OBIEE it can’t use the sequence numbers. Try with just a very simple basic example to see if it still ignore the sequences.
Thanks for the reply. I tried with some simple examples, but it still did not use the relative sequence number column that I provided. I used a number type column that is not sequence for absolute sequence number as I only expect OBIEE to use relative one for my case.
OBIEE 12.2.1.2.0 (no patch) clean install the sequence numbers where used directly. If it isn’t the case for you and your system is “clean” you can of course open a SR. (Just few minutes ago I saw a OTN forum thread about something like that from an Oracle employee, is it you? So opening a SR and asking your colleagues must be even easier than for clients…)
Sequence numbers will anyway not change much, most of the time it isn’t a solution for a slow query, so you aren’t missing I lot.
I use OBIEE12.2.1.2.0 clean install (no patch). So you mean I need a patch? It is me on the OTN forum. The reason why I want to use it is not for performance. The reason why I want to use it is because I can provide my own sequence. We have shifting calendar for 53 week requirement and the generated sequence by rank cannot meet that.
No, no patch needed as far as I know. Did you try setting a sort column? With a sort column the rank is supposed to happen on that one (or they just missed something big), and by that will return a correct rank. I guess it would be helpful if in the OTN thread you post all these details: version used, use case, current result example, logs of the current query highlighting the issue you with the current situation. It will help people giving better answers 😉
still could not figure out why it did not work for me. Have your tried on OBIEE 12.2.1.2.0 version without any patch?
Yes, it was tested on a clean install of 12.2.1.2.0 without any patching and just by adding 2-3 tables to the RPD of Sample Sales Lite (the default example one).